PID allocator bench marked
das@ [David Schultz] has done some benchmark of the different PID allocators recently being discussed on hackers@, and the result is available here.
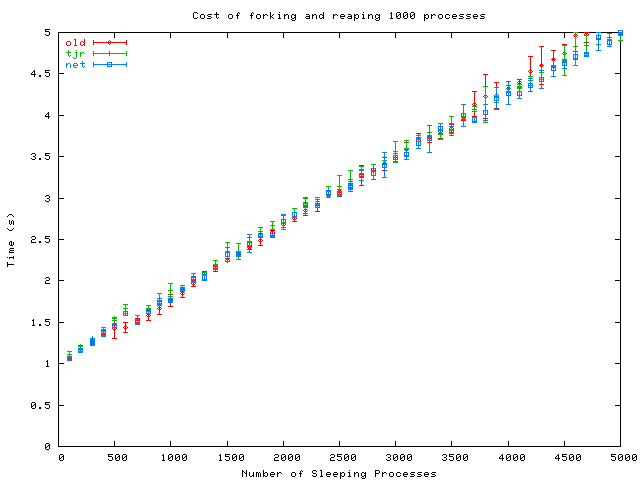
The forking and reaping 1000 processes is as follows (data by das@)
Cost of vfork’ing and reaping 10000 processes result in:
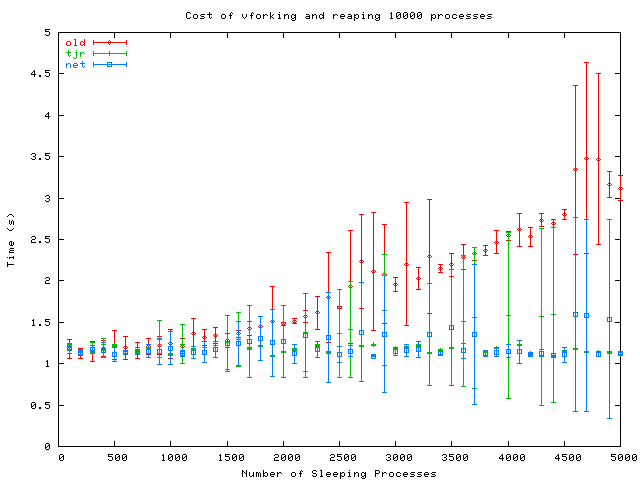
It’s clear that new implementations of PID allocator shows performance improvement. The benchmark suggests that junsu’s port of NetBSD PID allocator is a little better than tjr’s, while it’s a bit more complex than tjr’s implementation, too.
I still think junsu’s PID allocator is a bit better than tjr’s. According to the when we have 750+ processes, or more, the “net” implementation outperforms tjr’s. However, the simplicity of tjr’s allocator has earned both das@ and phk@’s applause, and it’s more likely to be a candidate MFp4.
What about SMP case? I’m looking for a test box for this, so if you can find one for me, contact me as possible.
There’re more interesting topics generated by the discussion. Among other things related to the performance benchmark, das points out that there’re two performance bottlenecks there. (1) wait4 was implemented not very well to perform a good job if there’re many childs waiting for reap. (2) pmap_remove_pages() needs more attention because it’s the most expensive part of exit() operation.